FEATURES
Multi-model
Support
The right intelligence for every task.

Not every enterprise request should be processed by the same model. Numero6 routes work across a private AI stack designed for different jobs: conversational reasoning, lightweight task execution, document retrieval, Web-grounded research, and code-assisted analysis — all inside your controlled infrastructure.
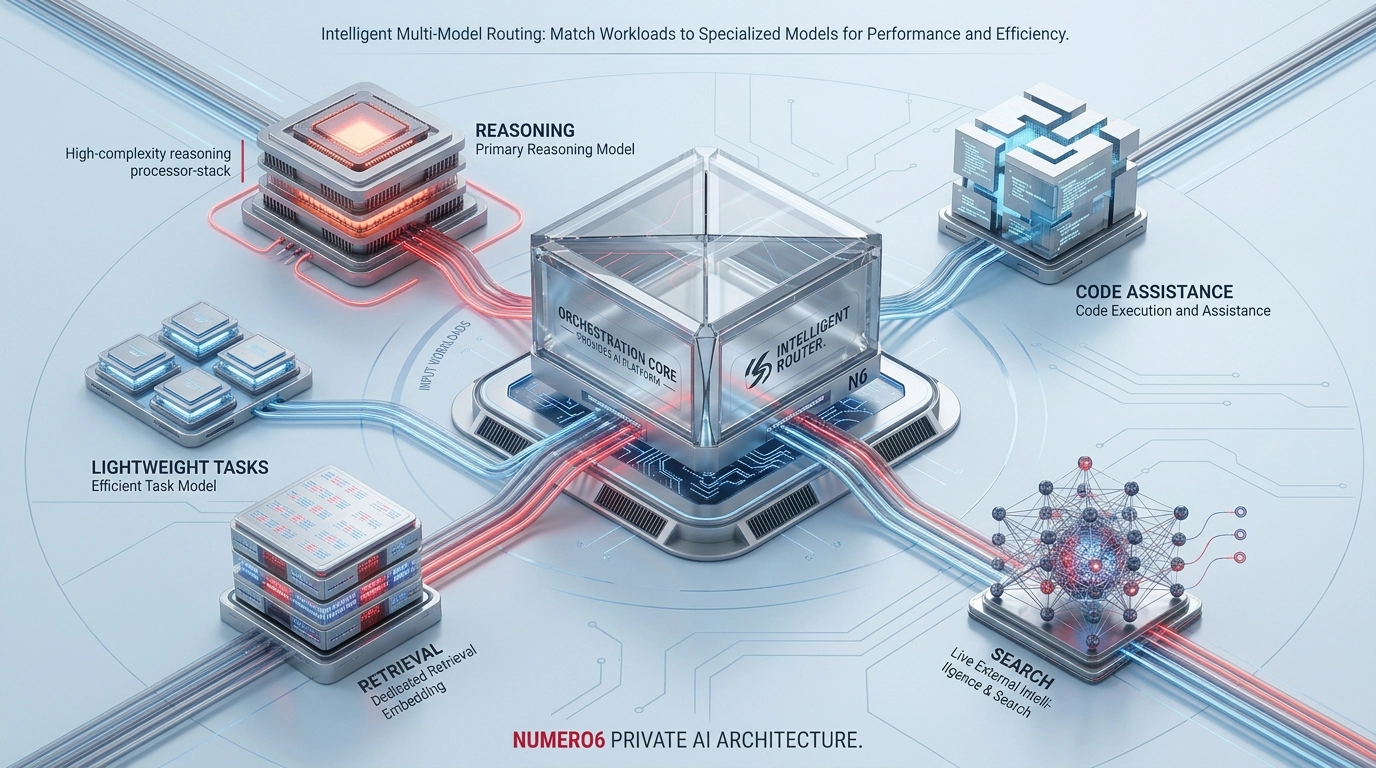
A customer question, a legal clause review, a Web-validated market check, and a document-heavy internal search do not have the same performance profile. Your infrastructure is built to handle those differences by combining Open WebUI as the user-facing control plane with Ollama on the host GPU, Qdrant for retrieval, SearXNG for private search, Apache Tika for document extraction, Jupyter for code execution, and mcpo for tool exposure.
In the current setup, Ollama runs natively to keep GPU access direct and latency low, while the surrounding services are containerized. The stack is already designed to support a primary LLM, a dedicated task model, and a separate embedding model as distinct roles instead of treating “the model” as a single monolith.
In the current setup, Ollama runs natively to keep GPU access direct and latency low, while the surrounding services are containerized. The stack is already designed to support a primary LLM, a dedicated task model, and a separate embedding model as distinct roles instead of treating “the model” as a single monolith.
How the Numero6 multi-model architecture works
Primary reasoning model — The platform can keep the main conversational model resident in VRAM for fast response and stable enterprise chat performance. The current Ollama tuning is designed to keep models loaded, enable Flash Attention, and sustain parallel request handling instead of constantly unloading and reloading weights.
Dedicated task model — Open WebUI is already configured with a separate task model for lightweight system tasks, which is a stronger real-world proof of multi-model design than simply listing several model names on a page.
Dedicated embedding pipeline — Retrieval does not rely on the chat model alone, because embeddings are generated with a specific model and stored in Qdrant for semantic search over enterprise content.
Retrieval and grounding layer — Uploaded documents are parsed through Apache Tika, indexed for RAG, and combined with Qdrant search so answers can be grounded in internal material rather than generic model memory.
Live external intelligence — When a query needs current information, SearXNG provides private metasearch capability without turning the user workflow into a public SaaS dependency.
Tool and action layer — Jupyter and mcpo extend the platform beyond chat, enabling code execution and tool-based workflows within the same environment.
This is not just model variety; it is model specialization. The service is sized so the platform can host the main LLMs, the embedding model, and the lightweight task model together with tuning for multiple parallel requests and persistent model residency in VRAM.
That means routing decisions can be made for speed as well as accuracy: lightweight tasks do not need to consume the most expensive reasoning path, while deeper analysis can still escalate to the stronger model when required. With an agentic configuration on top, that routing can become stateful and policy-driven, with explicit fallback, step-level control, and model selection based on workflow state rather than only on the UI choice.
That means routing decisions can be made for speed as well as accuracy: lightweight tasks do not need to consume the most expensive reasoning path, while deeper analysis can still escalate to the stronger model when required. With an agentic configuration on top, that routing can become stateful and policy-driven, with explicit fallback, step-level control, and model selection based on workflow state rather than only on the UI choice.

Ollama-managed models — Your dedicated Numero6 instance runs a curated selection of open-source models through Ollama, each optimised for specific use cases: conversational reasoning, instruction following, coding assistance, multilingual support, and more. Models include state-of-the-art open-source options such as Llama, Qwen, Gemma, Mistral, and others, selected and configured to maximise performance on your specific GPU tier.
vLLM for high-concurrency workloads — For enterprise scenarios requiring simultaneous inference, vLLM nodes can be integrated into your Numero6 instance. Switching from Ollama to vLLM unlocks server-grade optimizations: PagedAttention maximizes KV cache efficiency to support more concurrent users, while continuous batching eliminates the "bottleneck" effect of traditional request processing. Additionally, vLLM provides advanced tensor parallelism for seamless multi-GPU scaling and higher tokens-per-second throughput than is possible with Ollama.
External model aggregation — Customers who require specific models on dedicated compute nodes — whether for performance isolation, regulatory requirements, or specialised capabilities — can have those nodes provisioned and connected to their centralised Open WebUI instance. From the user or application perspective, it remains a single, unified AI service.
Model-level access control — Administrators can assign specific models to specific users, teams, or applications. A finance team might access only compliance-approved models; a development team might have access to code-specialised models.
No vendor lock-in — All models running on Numero6 are open-source. Model weights are not proprietary to any commercial provider. Your service is not dependent on any single vendor's continued availability, pricing decisions, or policy changes.
Enterprise AI is not about offering the longest list of model names. It is about sending each workload to the right execution path while keeping documents, search flows, tool calls, and operational control inside a private environment.
With Numero6, multi-model support is part of a broader architecture: user conversations in Open WebUI, retrieval through Qdrant, private web search through SearXNG, document extraction through Tika, code execution through Jupyter, and optional graph-based orchestration for more advanced agentic routing.
With Numero6, multi-model support is part of a broader architecture: user conversations in Open WebUI, retrieval through Qdrant, private web search through SearXNG, document extraction through Tika, code execution through Jupyter, and optional graph-based orchestration for more advanced agentic routing.