FEATURES
RAG &
Knowledge Base
AI that knows your business, running strictly inside your secure boundaries.

Standard large language models are extraordinarily capable — but they do not know your organization. They have not read your internal policies, your product documentation, your legal contracts, or your research archives. Out of the box, they can only guess. Retrieval-Augmented Generation (RAG) changes this.
RAG connects your AI model to a curated, living collection of your own documents — your Knowledge Base. When a user or an API asks a question, the system first retrieves the most relevant passages from your data in milliseconds, and then instructs the AI to generate an answer based only on that retrieved context.
The result is an AI that speaks with authority about your business, eliminating hallucinations and grounding every response in verifiable internal truth.
In the Numero6 platform, this entire process — from document parsing to vector embedding and final inference — happens within a completely isolated, private environment. Your data never trains public models, and your internal knowledge never leaves your infrastructure.
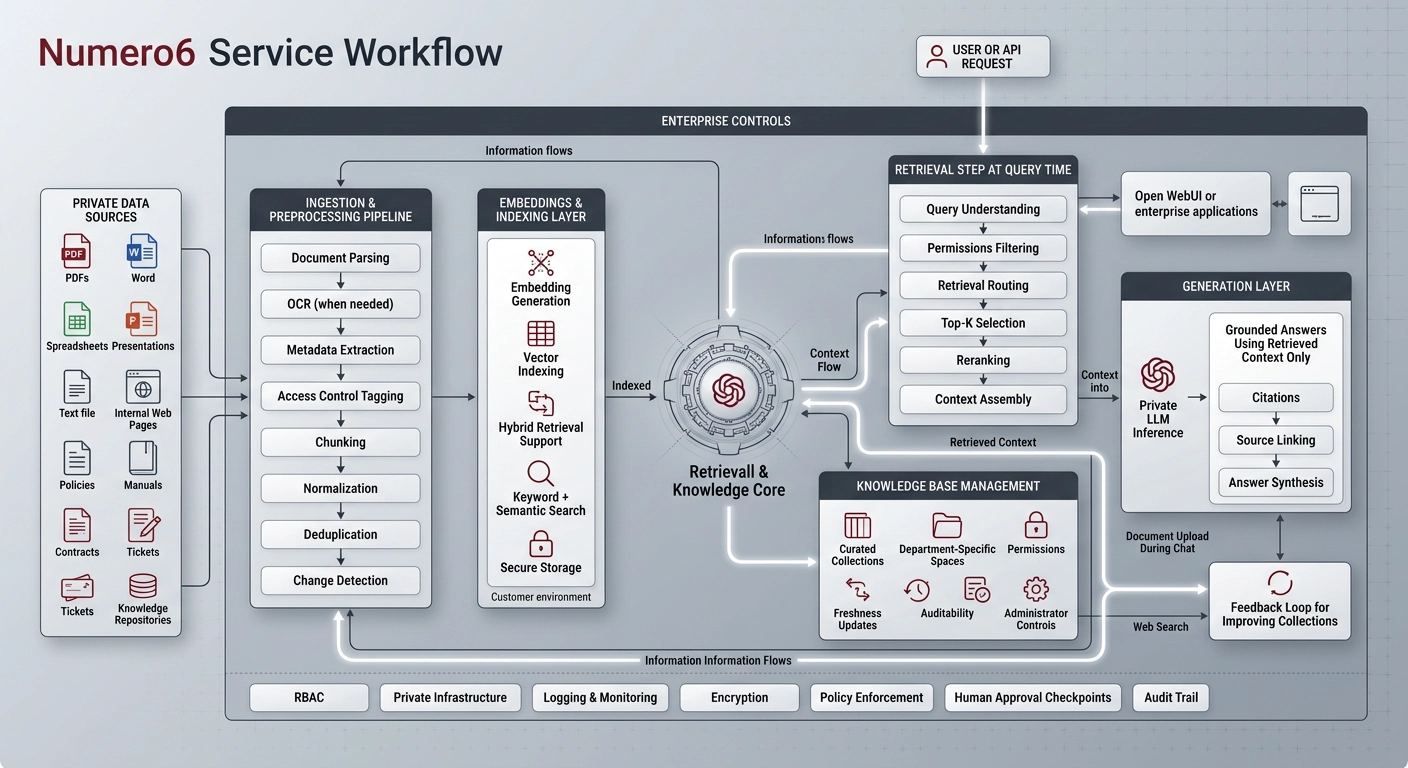
RAG connects your AI model to a curated, living collection of your own documents — your Knowledge Base. When a user or an API asks a question, the system first retrieves the most relevant passages from your data in milliseconds, and then instructs the AI to generate an answer based only on that retrieved context.
The result is an AI that speaks with authority about your business, eliminating hallucinations and grounding every response in verifiable internal truth.
In the Numero6 platform, this entire process — from document parsing to vector embedding and final inference — happens within a completely isolated, private environment. Your data never trains public models, and your internal knowledge never leaves your infrastructure.
When a user submits a query, the system does not simply search a static database. It executes a state-aware retrieval pipeline:
Intent & State Analysis – The engine evaluates the current conversation state, user permissions, and query complexity.
Dynamic Retrieval Routing – Based on freshness requirements and data sensitivity, it routes the request to the optimal source: local vector storage, web search, external APIs, or hybrid combinations.
Context Optimization – Retrieved passages are re-ranked, filtered by metadata, and injected into the context window using intelligent chunking and summarization.
Model Routing & Generation – The optimized context is passed to the best-suited inference model. Lightweight models handle routing and formatting; heavyweight models handle deep reasoning and synthesis.
Privacy-first processing — All document ingestion, embedding, and retrieval happens entirely within your dedicated Numero6 instance. Your documents never leave your environment.
State Persistence & Auditability – In agentic workflows, every retrieval, decision, and generation step is checkpointed. Conversations can be paused, resumed, or replayed deterministically — even after system interruptions.
Multi-format ingestion — Upload PDFs, Word documents, Excel spreadsheets, PowerPoint presentations, plain text files, markdown, and web pages directly into your knowledge base. The Numero6 pipeline automatically parses, chunks, and structures the content for optimal AI retrieval.
Advanced Semantic Search (Vector & Hybrid) — We do not rely on simple keyword matching. The platform uses dedicated, local embedding models (like nomic-embed-text) to translate your documents into dense vector representations. This means the AI understands the meaning and intent behind a query, retrieving relevant content even if the exact words differ.
Persistent, team-shared repositories — Knowledge bases are not just temporary uploads. They persist across sessions and can be logically separated. You can build global repositories for company-wide HR policies, and highly restricted repositories for executive legal contracts, managing access strictly via Role-Based Access Control (RBAC).
Per-conversation knowledge injection — Users are always in control of the context. Through the workspace interface, a user can activate specific knowledge bases for an individual conversation, ensuring the AI is contextualized only with the domain data relevant to the current task.
Citeable, transparent responses — Trust requires verification. When answering from the knowledge base, the Numero6 engine explicitly references its source material. Users can click on a citation to view the exact document and passage the AI used to formulate its response, providing full transparency for compliance-sensitive operations.
Enterprise API Access — Your knowledge base isn't locked behind a chat interface. Through the Numero6 Enterprise API, your own applications, internal portals, and automated agents can query the RAG system programmatically, injecting your private intelligence into your existing business workflows.
The fundamental flaw in public RAG solutions is data exposure. Sending proprietary documents to external cloud embeddings and external LLMs creates unacceptable compliance risks for enterprise data.
Numero6 is engineered differently. We deploy a fully sovereign RAG pipeline:
- Local Embeddings: Documents are vectorized using dedicated embedding models running on our isolated hardware dedicated to you.
- Local Vector Storage: Data is indexed in our secure, private vector databases (PostgreSQL/pgvector or Qdrant) within your isolated tenant network.
- Local Inference: The retrieved context is processed by private LLMs running on our dedicated GPUs, which are dedicated to you.
At no point does a single byte of your confidential documentation cross the public internet to third-party AI providers.
Internal policy and procedure assistants
Instant, accurate answers on HR, IT, and compliance protocols.
Instant, accurate answers on HR, IT, and compliance protocols.
Legal contract review and clause extraction
Rapidly search through thousands of historical agreements for specific terms.
Rapidly search through thousands of historical agreements for specific terms.
Medical protocol and guideline reference
Fast retrieval of clinical guidelines without exposing patient data frameworks.
Fast retrieval of clinical guidelines without exposing patient data frameworks.
Financial regulation and compliance querying
Cross-reference complex regulatory documents instantly.
Cross-reference complex regulatory documents instantly.
Product knowledge assistants for sales
Arm your sales and support teams with instant access to every spec sheet and manual.
Arm your sales and support teams with instant access to every spec sheet and manual.
Research archive querying for R&D
Unlock decades of siloed technical research, making past experiments searchable by concept.
Unlock decades of siloed technical research, making past experiments searchable by concept.